Desarrolla tu Primera Aplicación Web Guiada por Voz
Habla con tu aplicación y permite que te responda
Jul 20, 2020 · 14 minutes read · Follow @luixaviles
Hace algún tiempo atrás tuve el objetivo de implementar una aplicación web para poder escribir automáticamente lo que estoy hablando y permitir ejecutar acciones a través de comandos de voz. Pensé que sería una buena idea proporcionar una manera de escuchar las respuestas de la aplicación también. Después de hacer una investigación rápida, descubrí un par de APIs Web para resolver este problema.
En este artículo, explicaré cómo se pueden usar las APIs Web modernas para agregar la capacidad de hablar con tu aplicación web y permitir que te responda. Implementaremos la aplicación desde cero.

¿Qué es una API?
API es el acrónimo de Application Programming Interface. De acuerdo con el sitio MDN:
Las APIs son implementaciones disponibles en lenguajes de programación para perfmitir a los desarrolladores crear funcionalidades complejas más facilmente.
En palabras simples, las APIs proveen una manera de desarrollar aplicaciones complejas sin tener que aprender o implementar los detalles.
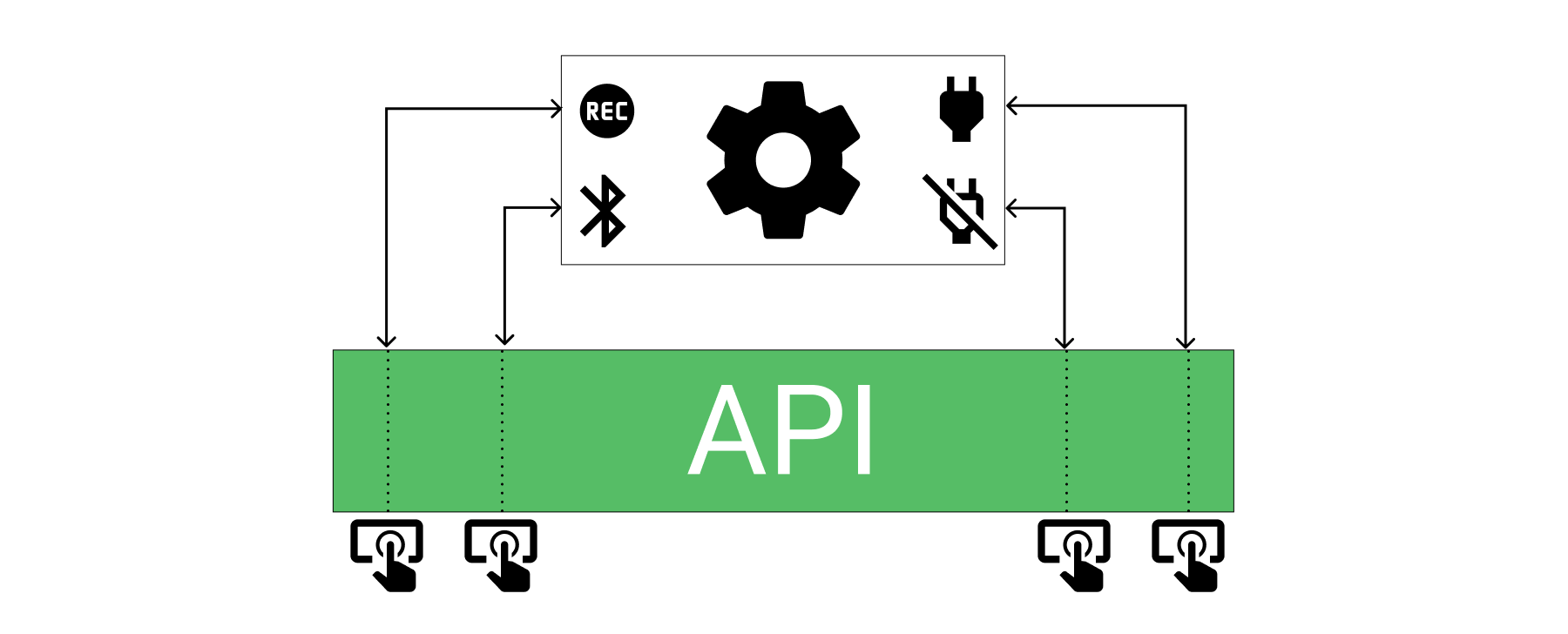
Describamos un ejemplo: acabas de comprar una cámara y sólo necesitas presionar los botones para encender, apagar, activar el Bluetooth e iniciar una grabación. Como puedes ver, estamos hablando de un dispositivo que cuenta con un circuito complejo que involucra sensores, lentes, administración de energía y otros detalles. Para usarlo, no necesitas trabajar a través de sus cables o administrar el circuito electrónico del equipo por ti mismo.
APIs Web
¿Alguna vez has usado fetch o un Service Worker? ¿O quizá hayas accedido al DOM desde JavaScript?
Bueno, puedes realizar tareas complejas basadas en estas funcionalidades, ya que forman parte de una extensa lista de APIs Web. Estas APIs no son parte de JavaScript, sin embargo, se pueden usar a través de este lenguaje de programación(o cualquier librería/framework basado en JavaScript).
Por otro lado, es posible que debas asegurarte de que tu navegador soporte una API antes de comenzar a crear tu aplicación. Por ejemplo, si planeas trabajar con fetch puedes ver qué navegadores o motores JavaScript lo soportan actualmente aquí.
Web Speech API

Como se puede ver en la imagen anterior, esta API puede ayudar en lo siguiente:
- Generar texto a partir del habla
- Usar el reconocimiento de voz como entrada
- Soportar dictado contínuo(puedes escribir una carta completa)
- Provee una interfaz de control para navegadores web
Para mayores detalles, por favor vea la especificación de Web Speech API.
La Interfaz SpeechSynthesis
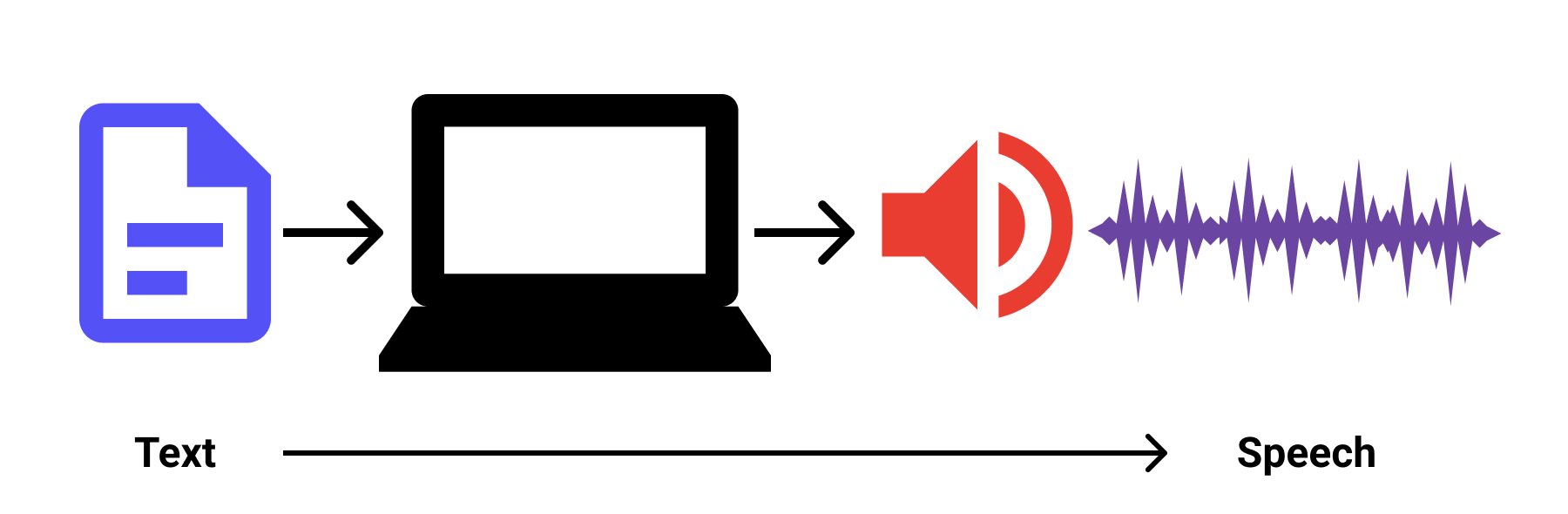
Ya se tiene la idea con la imagen anterior. La interfaz Web Speech Synthesis puede generar habla(salida) a partir de texto(entrada).
Para aprender más sobre esta interfaz, revisa la especificación.
Implementa la Aplicación Web
La aplicación estará basada en HTML, CSS y TypeScript como lenguaje de programación. Se usará la última versión de Angular junto con Angular Material para los componentes. También se definirá un enfoque de programación reactiva usando Observables y el AsyncPipe de Angular. Finalmente, se proporciona una implementación del Patrón Estrategia junto con otras funcionalidades.
Creando el Proyecto
Crearemos la aplicación web desde cero usando la última versión de Angular CLI:
ng new web-speech-angular --routing --style css --prefix wsa --strict
--routing: Genera un módulo para el manejo de rutas en el proyecto.--style: Especifica la extensión para los archivos de estilo.--prefix: Establece un prefijo para el selector de componentes.--strict: Disponible a partir de Angular 10. Habilita una verificación de tipos más estricta junto con optimizaciones en la compilación.
Agregando Angular Material
Agregar el soporte de Angular Material debería ser simple en este punto:
ng add @angular/material
Ahora podemos seguir algunas Pautas estructurales generales de la documentación de Angular para generar los módulos shared y material:
ng generate module shared --module app
ng generate module shared/material --module shared
Estos comandos generan la siguiente estructura de directorios en el proyecto:
|- src/
|- app/
|- shared/
|- material/
|- material.module.ts
|- shared.module.ts
Agregando el módulo web-speech
Es hora de agregar un nuevo módulo para definir los componentes necesarios para mostrar los controles de la aplicación.
ng generate module web-speech --module app
ng generate component web-speech
Luego, tendremos la siguiente estructura:
|- src/
|- app/
|- shared/
|- web-speech/
|- web-speech.module.ts
|- web-speech.component.ts|html|css
Agregando el directorio web-apis
Creemos una nueva carpeta para agrupar los servicios relacionados con las web APIs que vamos a utilizar. Además, definamos algunos archivos TypeScript para los idiomas, notificaciones, errores y eventos que soporta el nuevo servicio.
ng generate service shared/services/web-apis/speech-recognizer
Luego de ejecutar el comando anterior y crear los archivos para el modelo, la estructura se verá como sigue:
|- src/
|- app/
|- shared/
|- shared.module.ts
|- services/
|- web-apis/
|- speech-recognizer.service.ts
|- model/
|- languages.ts
|- speech-error.ts
|- speech-event.ts
|- speech-notification.ts
|- web-speech/
|- web-speech.module.ts
|- web-speech.component.ts|html|css
Definiendo el modelo para Notificaciones, Eventos y Errores
Dado que la especificación actual tiene una implementación en JavaScript, podemos proveer código TypeScript y tomar ventaja del tipado estático. Esto es imporante ya que el proyecto ha sido configurado con el modo strict habilitado para el compilador de TypeScript.
// languages.ts
export const languages = ['en-US', 'es-ES'];
export const defaultLanguage = languages[0];
// speech-error.ts
export enum SpeechError {
NoSpeech = 'no-speech',
AudioCapture = 'audio-capture',
NotAllowed = 'not-allowed',
Unknown = 'unknown'
}
// speech-event.ts
export enum SpeechEvent {
Start,
End,
FinalContent,
InterimContent
}
// speech-notification.ts
export interface SpeechNotification<T> {
event?: SpeechEvent;
error?: SpeechError;
content?: T;
}
Atención con el enumerado SpeechError. Las claves string coinciden con los valores actuales de la especificación SpeechRecognitionErrorEvent.
Creando el SpeechRecognizerService (Reconocimiento Asíncrono de Voz)
El objetivo principal será definir una abstracción de las funcionalidades que necesitamos para la aplicación:
- Definir una configuración básica para
SpeechRecognizerService(Una instancia dewebkitSpeechRecognitionque es soportada por Google Chrome). - Definir la configuración para el idioma.
- Capturar resultados intermedios mientras el usuario está hablando.
- Permitir iniciar y detener el servicio de reconocimiento de voz.
El código siguiente provee una implementación para cumplir con dichos requerimientos:
// speech-recognizer.service.ts
@Injectable({
providedIn: 'root',
})
export class SpeechRecognizerService {
recognition: SpeechRecognition;
language: string;
isListening = false;
constructor() {}
initialize(language: string): void {
this.recognition = new webkitSpeechRecognition();
this.recognition.continuous = true;
this.recognition.interimResults = true;
this.setLanguage(language);
}
setLanguage(language: string): void {
this.language = language;
this.recognition.lang = language;
}
start(): void {
this.recognition.start();
this.isListening = true;
}
stop(): void {
this.recognition.stop();
}
}
Ahora es el momento de proporcionar una API usando el paradigma de la Programación Reactiva usando Observables para un flujo contínuo de datos. Esto será útil para “captar” el texto inferido mientras el usuario habla continuamente(No necesitaremos extraer este contenido cada vez para ver si hay algo nuevo).
export class SpeechRecognizerService {
// La implementación anterior aqui...
onStart(): Observable<SpeechNotification<never>> {
if (!this.recognition) {
this.initialize(this.language);
}
return new Observable(observer => {
this.recognition.onstart = () => observer.next({
event: SpeechEvent.Start
});
});
}
onEnd(): Observable<SpeechNotification<never>> {
return new Observable(observer => {
this.recognition.onend = () => {
observer.next({
event: SpeechEvent.End
});
this.isListening = false;
};
});
}
onResult(): Observable<SpeechNotification<string>> {
return new Observable(observer => {
this.recognition.onresult = (event: SpeechRecognitionEvent) => {
let interimContent = '';
let finalContent = '';
for (let i = event.resultIndex; i < event.results.length; ++i) {
if (event.results[i].isFinal) {
finalContent += event.results[i][0].transcript;
observer.next({
event: SpeechEvent.FinalContent,
content: finalContent
});
} else {
interimContent += event.results[i][0].transcript;
observer.next({
event: SpeechEvent.InterimContent,
content: interimContent
});
}
}
};
});
}
onError(): Observable<SpeechNotification<never>> {
return new Observable(observer => {
this.recognition.onerror = (event) => {
const eventError: string = (event as any).error;
let error: SpeechError;
switch (eventError) {
case 'no-speech':
error = SpeechError.NoSpeech;
break;
case 'audio-capture':
error = SpeechError.AudioCapture;
break;
case 'not-allowed':
error = SpeechError.NotAllowed;
break;
default:
error = SpeechError.Unknown;
break;
}
observer.next({
error
});
};
});
}
}
En el código anterior, se escriben las funciones que retornan los Observables y funcionan a manera de “envolventes” para manejar los siguientes eventos definidos en la especificación:
recognition.onstart = function() { ... }
recognition.onend = function() { ... }
recognition.onresult = function(event) { ... }
recognition.onerror = function(event) { ... }
Para comprender mejor cómo trabajan estas funciones, consulte la especificación respectiva para SpeechRecognition Events, SpeechRecognitionResult y SpeechRecognitionErrorEvent.
Trabajando con el componente WebSpeechComponent
Ya contamos con el servicio SpeechRecognizerService disponible, es hora de definir el componente Angular:
// web-speech-component.ts
import { ChangeDetectionStrategy, Component, OnInit } from '@angular/core';
import { merge, Observable, Subject } from 'rxjs';
import { map, tap } from 'rxjs/operators';
import { defaultLanguage, languages } from '../shared/model/languages';
import { SpeechError } from '../shared/model/speech-error';
import { SpeechEvent } from '../shared/model/speech-event';
import { SpeechRecognizerService } from '../shared/web-apis/speech-recognizer.service';
@Component({
selector: 'wsa-web-speech',
templateUrl: './web-speech.component.html',
styleUrls: ['./web-speech.component.css'],
changeDetection: ChangeDetectionStrategy.OnPush,
})
export class WebSpeechComponent implements OnInit {
languages: string[] = languages;
currentLanguage: string = defaultLanguage; // Set the default language
totalTranscript: string; // The variable to accumulate all the recognized texts
transcript$: Observable<string>; // Shows the transcript in "real-time"
listening$: Observable<boolean>; // Changes to 'true'/'false' when the recognizer starts/stops
errorMessage$: Observable<string>; // An error from the Speech Recognizer
defaultError$ = new Subject<undefined>(); // Clean-up of the previous errors
constructor(private speechRecognizer: SpeechRecognizerService) {}
ngOnInit(): void {
// Initialize the speech recognizer with the default language
this.speechRecognizer.initialize(this.currentLanguage);
// Prepare observables to "catch" events, results and errors.
this.initRecognition();
}
start(): void {
if (this.speechRecognizer.isListening) {
this.stop();
return;
}
this.defaultError$.next(undefined);
this.speechRecognizer.start();
}
stop(): void {
this.speechRecognizer.stop();
}
selectLanguage(language: string): void {
if (this.speechRecognizer.isListening) {
this.stop();
}
this.currentLanguage = language;
this.speechRecognizer.setLanguage(this.currentLanguage);
}
}
En esencia, el código anterior muestra cómo definir los principales atributos y funciones para lograr lo siguiente:
- Permite cambiar el idioma para el reconocimiento de voz.
- Conoce cúando el servicio está “escuchando”.
- Permite iniciar y detener el servicio de reconocimiento de voz desde el contexto del componente.
La pregunta ahora es: ¿Cómo podemos obtener la transcripción(lo que el usuario está hablando en formato texto) y cómo puedo saber cuando el servicio de voz está escuchando? Además, ¿cómo sabemos si hay un error con el micrófono o la API en sí?
La respuesta es: usar los Observables del servicio SpeechRecognizerService. En lugar de usar la función subscribe con los mismos, podemos asignarlos a través del uso de Async Pipes en las plantillas más adelante.
// web-speech.component.ts
export class WebSpeechComponent implements OnInit {
// Previous code here...
private initRecognition(): void {
// "transcript$" now will receive every text(interim result) from the Speech API.
// Also, for every "Final Result"(from the speech), the code will append that text to the existing Text Area component.
this.transcript$ = this.speechRecognizer.onResult().pipe(
tap((notification) => {
if (notification.event === SpeechEvent.FinalContent) {
this.totalTranscript = this.totalTranscript
? `${this.totalTranscript}\n${notification.content?.trim()}`
: notification.content;
}
}),
map((notification) => notification.content || '')
);
// "listening$" will receive 'true' when the Speech API starts and 'false' when it's finished.
this.listening$ = merge(
this.speechRecognizer.onStart(),
this.speechRecognizer.onEnd()
).pipe(
map((notification) => notification.event === SpeechEvent.Start)
);
// "errorMessage$" will receive any error from Speech API and it will map that value to a meaningful message for the user
this.errorMessage$ = merge(
this.speechRecognizer.onError(),
this.defaultError$
).pipe(
map((data) => {
if (data === undefined) {
return '';
}
let message;
switch (data.error) {
case SpeechError.NotAllowed:
message = `Cannot run the demo.
Your browser is not authorized to access your microphone.
Verify that your browser has access to your microphone and try again.`;
break;
case SpeechError.NoSpeech:
message = `No speech has been detected. Please try again.`;
break;
case SpeechError.AudioCapture:
message = `Microphone is not available. Plese verify the connection of your microphone and try again.`;
break;
default:
message = '';
break;
}
return message;
})
);
}
}
La Plantilla para el Componente WebSpeechComponent
Como mencionamos anteriormente, la plantilla del componente hará uso de Async Pipes:
<section>
<mat-card *ngIf="errorMessage$| async as errorMessage" class="notification">{{errorMessage}}</mat-card>
</section>
<section>
<mat-form-field>
<mat-label>Select your language</mat-label>
<mat-select [(value)]="currentLanguage">
<mat-option *ngFor="let language of languages" [value]="language" (click)="selectLanguage(language)">
{{language}}
</mat-option>
</mat-select>
</mat-form-field>
</section>
<section>
<button mat-fab *ngIf="listening$ | async; else mic" (click)="stop()">
<mat-icon class="soundwave">mic</mat-icon>
</button>
<ng-template #mic>
<button mat-fab (click)="start()">
<mat-icon>mic</mat-icon>
</button>
</ng-template>
</section>
<section *ngIf="transcript$ | async">
<mat-card class="notification mat-elevation-z4">{{transcript$ | async}}</mat-card>
</section>
<section>
<mat-form-field class="speech-result-width">
<textarea matInput [value]="totalTranscript || ''" placeholder="Speech Input Result" rows="15" disabled="false"></textarea>
</mat-form-field>
</section>
En este punto, la aplicación está lista para habilitar el micrófono del navegador y escuchar al usuario.
Agregando el Servicio SpeechSynthesizerService(Texto-A-Voz)
Empecemos creando el servicio primero:
ng generate service shared/services/web-apis/speech-synthesizer
Agrega el siguiente código al archivo TypeScript:
// speech-synthesizer.ts
import { Injectable } from '@angular/core';
@Injectable({
providedIn: 'root',
})
export class SpeechSynthesizerService {
speechSynthesizer!: SpeechSynthesisUtterance;
constructor() {
this.initSynthesis();
}
initSynthesis(): void {
this.speechSynthesizer = new SpeechSynthesisUtterance();
this.speechSynthesizer.volume = 1;
this.speechSynthesizer.rate = 1;
this.speechSynthesizer.pitch = 0.2;
}
speak(message: string, language: string): void {
this.speechSynthesizer.lang = language;
this.speechSynthesizer.text = message;
speechSynthesis.speak(this.speechSynthesizer);
}
}
Ahora la aplicación podrá hablar contigo. Podemos llamar a este servicio cuando la aplicación esté lista para realizar una acción guiada por comandos de voz. Además, podemos confirmar cuándo se han realizado las acciones o incluso pedir parámetros antes de ejecutarlas.
El siguiente objetivo es definir un conjunto de comandos de voz para realizar acciones sobre la aplicación.
Definiendo Acciones a través de Estrategias
Pensemos en las principales acciones a ser ejecutadas via comandos de voz en la aplicación:
- La aplicación puede cambiar el tema predeterminado por cualquier otro tema disponible de Angular Material.
- La aplicación puede cambiar el título principal
- Al mismo tiempo, cada resultado final se adjunta al área de texto principal
Existen diferentes formas de diseñar una solución para este contexto. En esta oportunidad, pensemos en definir algunas estrategias para cambiar el título y el tema de la aplicación.
Por ahora, la palabra clave es Estrategia. Después de hechar un vistazo al mundo de los Patrones de Diseño está claro que podemos usar el Patron Estrategia para implementar dicha solución.
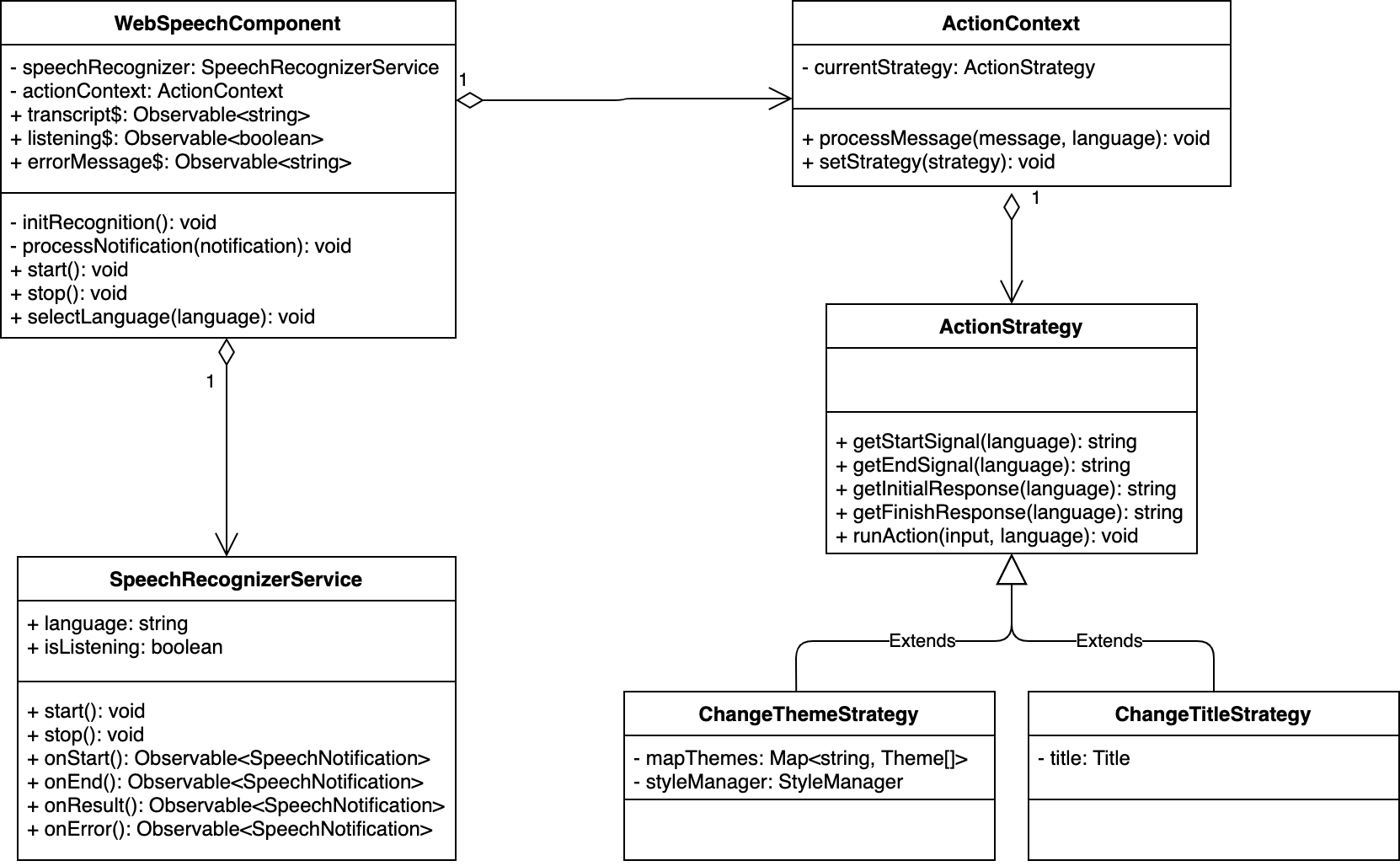
Agregando el Servicio ActionContext y las respectivas Estrategias
Procedamos a crear las clases ActionContext, ActionStrategy, ChangeThemeStrategy y ChangeTitleStrategy:
ng generate class shared/services/action/action-context
ng generate class shared/services/action/action-strategy
ng generate class shared/services/action/change-theme-strategy
ng generate class shared/services/action/change-title-strategy
// action-context.ts
@Injectable({
providedIn: 'root',
})
export class ActionContext {
private currentStrategy?: ActionStrategy;
constructor(
private changeThemeStrategy: ChangeThemeStrategy,
private changeTitleStrategy: ChangeTitleStrategy,
private titleService: Title,
private speechSynthesizer: SpeechSynthesizerService
) {
this.changeTitleStrategy.titleService = titleService;
}
processMessage(message: string, language: string): void {
const msg = message.toLowerCase();
const hasChangedStrategy = this.hasChangedStrategy(msg, language);
let isFinishSignal = false;
if (!hasChangedStrategy) {
isFinishSignal = this.isFinishSignal(msg, language);
}
if (!hasChangedStrategy && !isFinishSignal) {
this.runAction(message, language);
}
}
runAction(input: string, language: string): void {
if (this.currentStrategy) {
this.currentStrategy.runAction(input, language);
}
}
setStrategy(strategy: ActionStrategy | undefined): void {
this.currentStrategy = strategy;
}
// Se omiten los métodos privados. Por favor referirse al repositorio para ver todo el código relacionado
// action-strategy.ts
export abstract class ActionStrategy {
protected mapStartSignal: Map<string, string> = new Map<string, string>();
protected mapEndSignal: Map<string, string> = new Map<string, string>();
protected mapInitResponse: Map<string, string> = new Map<string, string>();
protected mapFinishResponse: Map<string, string> = new Map<string, string>();
protected mapActionDone: Map<string, string> = new Map<string, string>();
constructor() {
this.mapFinishResponse.set('en-US', 'Your action has been completed.');
this.mapFinishResponse.set('es-ES', 'La accion ha sido finalizada.');
}
getStartSignal(language: string): string {
return this.mapStartSignal.get(language) || '';
}
getEndSignal(language: string): string {
return this.mapEndSignal.get(language) || '';
}
getInitialResponse(language: string): string {
return this.mapInitResponse.get(language) || '';
}
getFinishResponse(language: string): string {
return this.mapFinishResponse.get(language) || '';
}
abstract runAction(input: string, language: string): void;
}
// change-theme-strategy.ts
@Injectable({
providedIn: 'root',
})
export class ChangeThemeStrategy extends ActionStrategy {
private mapThemes: Map<string, Theme[]> = new Map<string, Theme[]>();
private styleManager: StyleManager = new StyleManager();
constructor(private speechSynthesizer: SpeechSynthesizerService) {
super();
this.mapStartSignal.set('en-US', 'perform change theme');
this.mapStartSignal.set('es-ES', 'iniciar cambio de tema');
this.mapEndSignal.set('en-US', 'finish change theme');
this.mapEndSignal.set('es-ES', 'finalizar cambio de tema');
this.mapInitResponse.set('en-US', 'Please, tell me your theme name.');
this.mapInitResponse.set('es-ES', 'Por favor, mencione el nombre de tema.');
this.mapActionDone.set('en-US', 'Changing Theme of the Application to');
this.mapActionDone.set('es-ES', 'Cambiando el tema de la Aplicación a');
this.mapThemes.set('en-US', [
{
keyword: 'deep purple',
href: 'deeppurple-amber.css',
}
]);
this.mapThemes.set('es-ES', [
{
keyword: 'púrpura',
href: 'deeppurple-amber.css',
}
]);
}
runAction(input: string, language: string): void {
const themes = this.mapThemes.get(language) || [];
const theme = themes.find((th) => {
return input.toLocaleLowerCase() === th.keyword;
});
if (theme) {
this.styleManager.removeStyle('theme');
this.styleManager.setStyle('theme', `assets/theme/${theme.href}`);
this.speechSynthesizer.speak(
`${this.mapActionDone.get(language)}: ${theme.keyword}`,
language
);
}
}
}
// change-title-strategy.ts
@Injectable({
providedIn: 'root',
})
export class ChangeTitleStrategy extends ActionStrategy {
private title?: Title;
constructor(private speechSynthesizer: SpeechSynthesizerService) {
super();
this.mapStartSignal.set('en-US', 'perform change title');
this.mapStartSignal.set('es-ES', 'iniciar cambio de título');
this.mapEndSignal.set('en-US', 'finish change title');
this.mapEndSignal.set('es-ES', 'finalizar cambio de título');
this.mapInitResponse.set('en-US', 'Please, tell me the new title');
this.mapInitResponse.set('es-ES', 'Por favor, mencione el nuevo título');
this.mapActionDone.set('en-US', 'Changing title of the Application to');
this.mapActionDone.set('es-ES', 'Cambiando el título de la Aplicación a');
}
set titleService(title: Title) {
this.title = title;
}
runAction(input: string, language: string): void {
this.title?.setTitle(input);
this.speechSynthesizer.speak(
`${this.mapActionDone.get(language)}: ${input}`,
language
);
}
}
Presta atención a los usos del servicio SpeechSynthesizerService y los lugares en los que se invoca la función speak. Justo en ese momento, la aplicación usará tus altavoces para responder a la acción.
Código Fuente y Live Demo
Código Fuente
Encuentra el proyecto complete en mi repositorio de GitHub: https://github.com/luixaviles/web-speech-angular. No olvides regalarme una estrella ⭐️ o enviar un Pull Request si decides contribuir con alguna característica o mejora.
Live Demo
Abre tu navegador Google Chrome y ve a https://luixaviles.com/web-speech-angular/. Revisa las notas de ayuda dentro la aplicación y prueba el reconocimiento de voz en inglés y español.
Palabras Finales
Aunque el proyecto se ha escrito usando Angular y TypeScript, puedes aplicar estos conceptos junto con las APIs web con cualquier librería o framework JavaScript.

Si te ha gustado el post, puedes compartirlo con tus amigos o en las redes sociales.
Puedes seguirme en Twitter y GitHub para conocer más de mi trabajo.
¡Gracias por leer!