Build Your First Voice-Driven Web Application
Talk to your web app and allow it to respond to you
Jul 20, 2020 · 14 minutes read · Follow @luixaviles
Some time ago I had the goal to implement a web application to be able to write what I’m speaking automatically and allow to execute actions through my voice commands. I thought it was a good idea to provide a way to listen to some feedback from the application too. After doing quick research I discovered a couple of Web APIs to solve this problem.
In this post, I will explain how you can use modern Web APIs to add the nice capability to speak to your web application and allow it to respond to you. We will implement the app from scratch.

What is an API?
API is the acronym for Application Programming Interface. According to MDN website:
APIs are constructs made available in programming languages to allow developers to create complex functionality more easily.
In simple words, APIs provide a way to create complex applications without having to learn or implement the details.
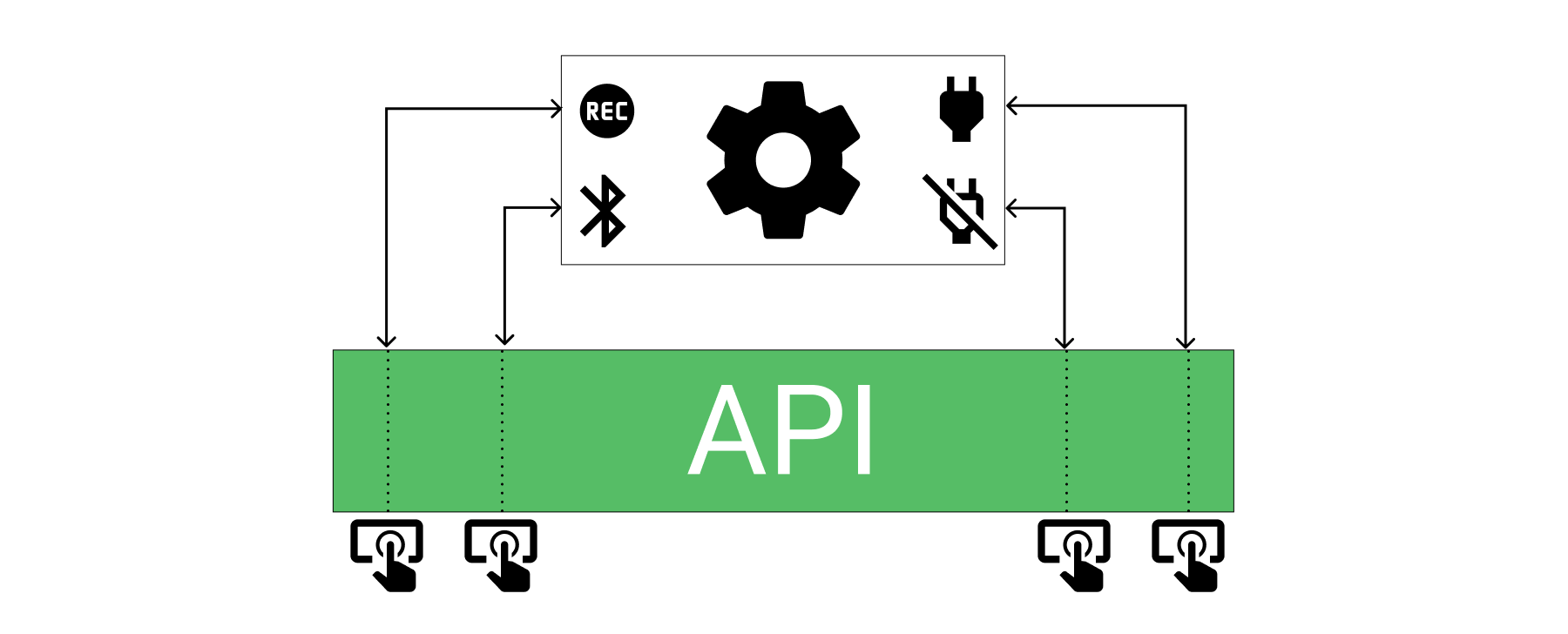
Let’s describe an example, you just bought a camera and you only need to press buttons to turn-on, turn-off, activate the Bluetooth, and start recording. As you can see, we’re talking about a device that has a complex circuit that involves sensors, lenses, power management, and other details. You don’t need to work through these wiring or manage the circuit itself.
Web APIs
Have you ever used fetch or a Service Worker? Maybe you used or accessed the DOM from JavaScript?
Well, you can accomplish complex tasks based on those features since they are part of an extensive list of Web APIs. These APIs are not part of JavaScript, however, you can use them through this programming language(or any other JavaScript-based library/framework).
On the other hand, you may need to make sure a Web API is fully supported by your web browser before to start building an application based on it. For example, if you are planning to work with fetch, you can see what browsers or JavaScript engines support it.
The Web Speech API

As you can see in the previous image, this Web API can help you with the following:
- Generate speech-to-text output
- Uses speech recognition as input
- Supports continuous dictation(You can write a complete letter)
- Control interface for web browsers
For more details, please see the Web Speech API specification.
The SpeechSynthesis Interface
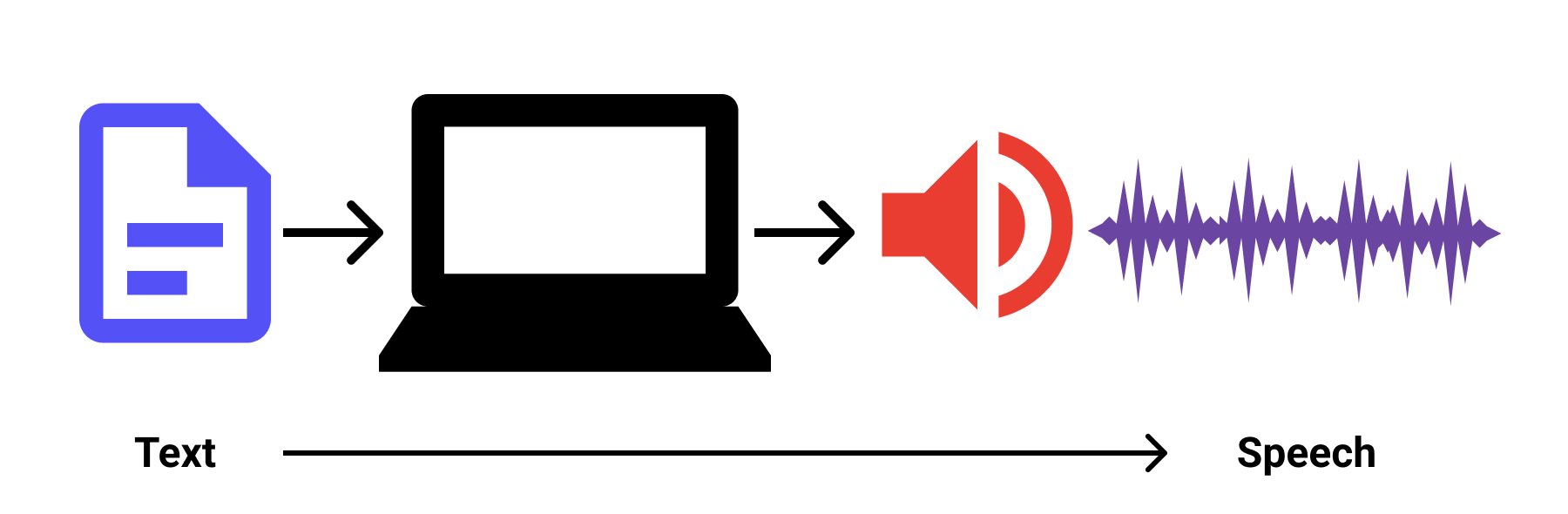
You got the idea with the above image. The Web Speech Synthesis interface can generate a text-to-speech output.
Please refer to the specification to learn more about this interface.
Watch The Video
Implement the Web Application
The application will be based on HTML, CSS, and TypeScript as the programming language. We’ll use the latest Angular version through Angular Material components. Also, We will define a reactive programming approach using Observables and the AsyncPipe from Angular. Finally, we will provide a Strategy pattern implementation among other features.
Creating the project
Let’s create the web application from scratch using the latest Angular CLI:
ng new web-speech-angular --routing --style css --prefix wsa --strict
--routing: Generates a routing module for the project.--style: The file extension for style files.--prefix: Set a prefix for the component selectors--strict: Available from Angular 10. Enable a stricter type checking and build optimization options.
Adding Angular Material
Adding Angular Material would be simple at this point:
ng add @angular/material
Now, we can follow the Overall structural guidelines from Angular to generate shared and material modules:
ng generate module shared --module app
ng generate module shared/material --module shared
These commands will generate the following structure in your project:
|- src/
|- app/
|- shared/
|- material/
|- material.module.ts
|- shared.module.ts
Adding the web-speech module
It’s time to add a new module to define the components needed to display the controls of the app.
ng generate module web-speech --module app
ng generate component web-speech
Now we will have the following structure:
|- src/
|- app/
|- shared/
|- web-speech/
|- web-speech.module.ts
|- web-speech.component.ts|html|css
Adding the web-apis directory
Let’s create a new folder to group services related to the Web APIs we are going to use. Also, let’s define some TypeScript files for the languages, Notifications, Errors and Events to be supported by the new service.
ng generate service shared/services/web-apis/speech-recognizer
After run the previous command and create the model files, the structure will be as follows:
|- src/
|- app/
|- shared/
|- shared.module.ts
|- services/
|- web-apis/
|- speech-recognizer.service.ts
|- model/
|- languages.ts
|- speech-error.ts
|- speech-event.ts
|- speech-notification.ts
|- web-speech/
|- web-speech.module.ts
|- web-speech.component.ts|html|css
Modeling Notifications, Events and Errors
Since the current specification is written in JavaScript, we can provide some TypeScript code to take advantage of the typing. This is even more important since the project has been configured with the strict mode enabled for TypeScript.
// languages.ts
export const languages = ['en-US', 'es-ES'];
export const defaultLanguage = languages[0];
// speech-error.ts
export enum SpeechError {
NoSpeech = 'no-speech',
AudioCapture = 'audio-capture',
NotAllowed = 'not-allowed',
Unknown = 'unknown'
}
// speech-event.ts
export enum SpeechEvent {
Start,
End,
FinalContent,
InterimContent
}
// speech-notification.ts
export interface SpeechNotification<T> {
event?: SpeechEvent;
error?: SpeechError;
content?: T;
}
Pay attention to SpeechError enum. The string keys match with actual values from the SpeechRecognitionErrorEvent specification.
Creating the SpeechRecognizerService (Asynchronous Speech Recognition)
The main goal would be to define an abstraction of the functionality we’ll need for the application:
- Define a basic configuration for the
SpeechRecognizerService(awebkitSpeechRecognitioninstance which is supported by Google Chrome). - Define a language configuration.
- Catch interim and final results.
- Allow start and stop the recognizer service.
The following code provides an implementation for those requirements:
// speech-recognizer.service.ts
@Injectable({
providedIn: 'root',
})
export class SpeechRecognizerService {
recognition: SpeechRecognition;
language: string;
isListening = false;
constructor() {}
initialize(language: string): void {
this.recognition = new webkitSpeechRecognition();
this.recognition.continuous = true;
this.recognition.interimResults = true;
this.setLanguage(language);
}
setLanguage(language: string): void {
this.language = language;
this.recognition.lang = language;
}
start(): void {
this.recognition.start();
this.isListening = true;
}
stop(): void {
this.recognition.stop();
}
}
Now it is time to provide a Reactive Programming oriented API to use Observables for a continuous data flow. This will be helpful to “catch” the inferred text while the user is continuously talking(We won’t need to pull values every time to see if there is something new).
export class SpeechRecognizerService {
// previous implementation here...
onStart(): Observable<SpeechNotification<never>> {
if (!this.recognition) {
this.initialize(this.language);
}
return new Observable(observer => {
this.recognition.onstart = () => observer.next({
event: SpeechEvent.Start
});
});
}
onEnd(): Observable<SpeechNotification<never>> {
return new Observable(observer => {
this.recognition.onend = () => {
observer.next({
event: SpeechEvent.End
});
this.isListening = false;
};
});
}
onResult(): Observable<SpeechNotification<string>> {
return new Observable(observer => {
this.recognition.onresult = (event: SpeechRecognitionEvent) => {
let interimContent = '';
let finalContent = '';
for (let i = event.resultIndex; i < event.results.length; ++i) {
if (event.results[i].isFinal) {
finalContent += event.results[i][0].transcript;
observer.next({
event: SpeechEvent.FinalContent,
content: finalContent
});
} else {
interimContent += event.results[i][0].transcript;
observer.next({
event: SpeechEvent.InterimContent,
content: interimContent
});
}
}
};
});
}
onError(): Observable<SpeechNotification<never>> {
return new Observable(observer => {
this.recognition.onerror = (event) => {
const eventError: string = (event as any).error;
let error: SpeechError;
switch (eventError) {
case 'no-speech':
error = SpeechError.NoSpeech;
break;
case 'audio-capture':
error = SpeechError.AudioCapture;
break;
case 'not-allowed':
error = SpeechError.NotAllowed;
break;
default:
error = SpeechError.Unknown;
break;
}
observer.next({
error
});
};
});
}
}
In the previous code we’re writing wrapper functions that return Observables to manage the following event handlers:
recognition.onstart = function() { ... }
recognition.onend = function() { ... }
recognition.onresult = function(event) { ... }
recognition.onerror = function(event) { ... }
To understand better how these functions work, please see the API Specification for SpeechRecognition Events, the SpeechRecognitionResult and the SpeechRecognitionErrorEvent.
Working on the WebSpeechComponent
Since we have the SpeechRecognizerService already available, it’s time to define the Angular Component:
// web-speech-component.ts
import { ChangeDetectionStrategy, Component, OnInit } from '@angular/core';
import { merge, Observable, Subject } from 'rxjs';
import { map, tap } from 'rxjs/operators';
import { defaultLanguage, languages } from '../shared/model/languages';
import { SpeechError } from '../shared/model/speech-error';
import { SpeechEvent } from '../shared/model/speech-event';
import { SpeechRecognizerService } from '../shared/web-apis/speech-recognizer.service';
@Component({
selector: 'wsa-web-speech',
templateUrl: './web-speech.component.html',
styleUrls: ['./web-speech.component.css'],
changeDetection: ChangeDetectionStrategy.OnPush,
})
export class WebSpeechComponent implements OnInit {
languages: string[] = languages;
currentLanguage: string = defaultLanguage; // Set the default language
totalTranscript: string; // The variable to accumulate all the recognized texts
transcript$: Observable<string>; // Shows the transcript in "real-time"
listening$: Observable<boolean>; // Changes to 'true'/'false' when the recognizer starts/stops
errorMessage$: Observable<string>; // An error from the Speech Recognizer
defaultError$ = new Subject<undefined>(); // Clean-up of the previous errors
constructor(private speechRecognizer: SpeechRecognizerService) {}
ngOnInit(): void {
// Initialize the speech recognizer with the default language
this.speechRecognizer.initialize(this.currentLanguage);
// Prepare observables to "catch" events, results and errors.
this.initRecognition();
}
start(): void {
if (this.speechRecognizer.isListening) {
this.stop();
return;
}
this.defaultError$.next(undefined);
this.speechRecognizer.start();
}
stop(): void {
this.speechRecognizer.stop();
}
selectLanguage(language: string): void {
if (this.speechRecognizer.isListening) {
this.stop();
}
this.currentLanguage = language;
this.speechRecognizer.setLanguage(this.currentLanguage);
}
}
In essence, the previous code shows how to define the main attributes and functions to accomplish:
- Allow switching the language for Speech Recognition.
- Know when the SpeechRecognizer is “listening”.
- Allow start and stop the SpeechRecognizer from the component context.
The question now is: How can we get the transcript(what the user is talking in text) and how may I know when the Speech service is listening? Also, How we know if there is an error with the microphone or the API itself?
The answer is: Using the Observables from the SpeechRecognizerService. Instead of using subscribe, let’s get and assign the Observables from the service, which will be used through the Async Pipes in the template later.
// web-speech.component.ts
export class WebSpeechComponent implements OnInit {
// Previous code here...
private initRecognition(): void {
// "transcript$" now will receive every text(interim result) from the Speech API.
// Also, for every "Final Result"(from the speech), the code will append that text to the existing Text Area component.
this.transcript$ = this.speechRecognizer.onResult().pipe(
tap((notification) => {
if (notification.event === SpeechEvent.FinalContent) {
this.totalTranscript = this.totalTranscript
? `${this.totalTranscript}\n${notification.content?.trim()}`
: notification.content;
}
}),
map((notification) => notification.content || '')
);
// "listening$" will receive 'true' when the Speech API starts and 'false' when it's finished.
this.listening$ = merge(
this.speechRecognizer.onStart(),
this.speechRecognizer.onEnd()
).pipe(
map((notification) => notification.event === SpeechEvent.Start)
);
// "errorMessage$" will receive any error from Speech API and it will map that value to a meaningful message for the user
this.errorMessage$ = merge(
this.speechRecognizer.onError(),
this.defaultError$
).pipe(
map((data) => {
if (data === undefined) {
return '';
}
let message;
switch (data.error) {
case SpeechError.NotAllowed:
message = `Cannot run the demo.
Your browser is not authorized to access your microphone.
Verify that your browser has access to your microphone and try again.`;
break;
case SpeechError.NoSpeech:
message = `No speech has been detected. Please try again.`;
break;
case SpeechError.AudioCapture:
message = `Microphone is not available. Plese verify the connection of your microphone and try again.`;
break;
default:
message = '';
break;
}
return message;
})
);
}
}
The Template for the WebSpeechComponent
As we said before, the component’s template will be powered by Async Pipes:
<section>
<mat-card *ngIf="errorMessage$| async as errorMessage" class="notification">{{errorMessage}}</mat-card>
</section>
<section>
<mat-form-field>
<mat-label>Select your language</mat-label>
<mat-select [(value)]="currentLanguage">
<mat-option *ngFor="let language of languages" [value]="language" (click)="selectLanguage(language)">
{{language}}
</mat-option>
</mat-select>
</mat-form-field>
</section>
<section>
<button mat-fab *ngIf="listening$ | async; else mic" (click)="stop()">
<mat-icon class="soundwave">mic</mat-icon>
</button>
<ng-template #mic>
<button mat-fab (click)="start()">
<mat-icon>mic</mat-icon>
</button>
</ng-template>
</section>
<section *ngIf="transcript$ | async">
<mat-card class="notification mat-elevation-z4">{{transcript$ | async}}</mat-card>
</section>
<section>
<mat-form-field class="speech-result-width">
<textarea matInput [value]="totalTranscript || ''" placeholder="Speech Input Result" rows="15" disabled="false"></textarea>
</mat-form-field>
</section>
At this point, the app is ready to enable the microphone and listen your voice!
Adding the SpeechSynthesizerService(Text-to-Speech)
Let’s create the service first:
ng generate service shared/services/web-apis/speech-synthesizer
Add the following code into that file.
// speech-synthesizer.ts
import { Injectable } from '@angular/core';
@Injectable({
providedIn: 'root',
})
export class SpeechSynthesizerService {
speechSynthesizer!: SpeechSynthesisUtterance;
constructor() {
this.initSynthesis();
}
initSynthesis(): void {
this.speechSynthesizer = new SpeechSynthesisUtterance();
this.speechSynthesizer.volume = 1;
this.speechSynthesizer.rate = 1;
this.speechSynthesizer.pitch = 0.2;
}
speak(message: string, language: string): void {
this.speechSynthesizer.lang = language;
this.speechSynthesizer.text = message;
speechSynthesis.speak(this.speechSynthesizer);
}
}
Now the application will be able to talk to you. We can call this service when the application is ready to perform a voice-driven action. Also, we can confirm when the actions have been performed or even ask for parameters.
The next goal is to define a set of voice commands to perform actions over the application.
Define the Actions through Strategies
Let’s think about the main actions to be performed by voice commands in the application:
- The app can change the default theme by any other theme available from Angular Material.
- The app can change the title property of the application.
- At the same time, we should be able to attach every final result over the existing Text Area component.
There are different ways to design a solution to this context. In this case, let’s think to define some strategies to change the theme and title of the application.
For now, Strategy is our favorite keyword. After taking a look in the world of Design Patterns it’s clear we can use the Strategy Pattern for the solution.
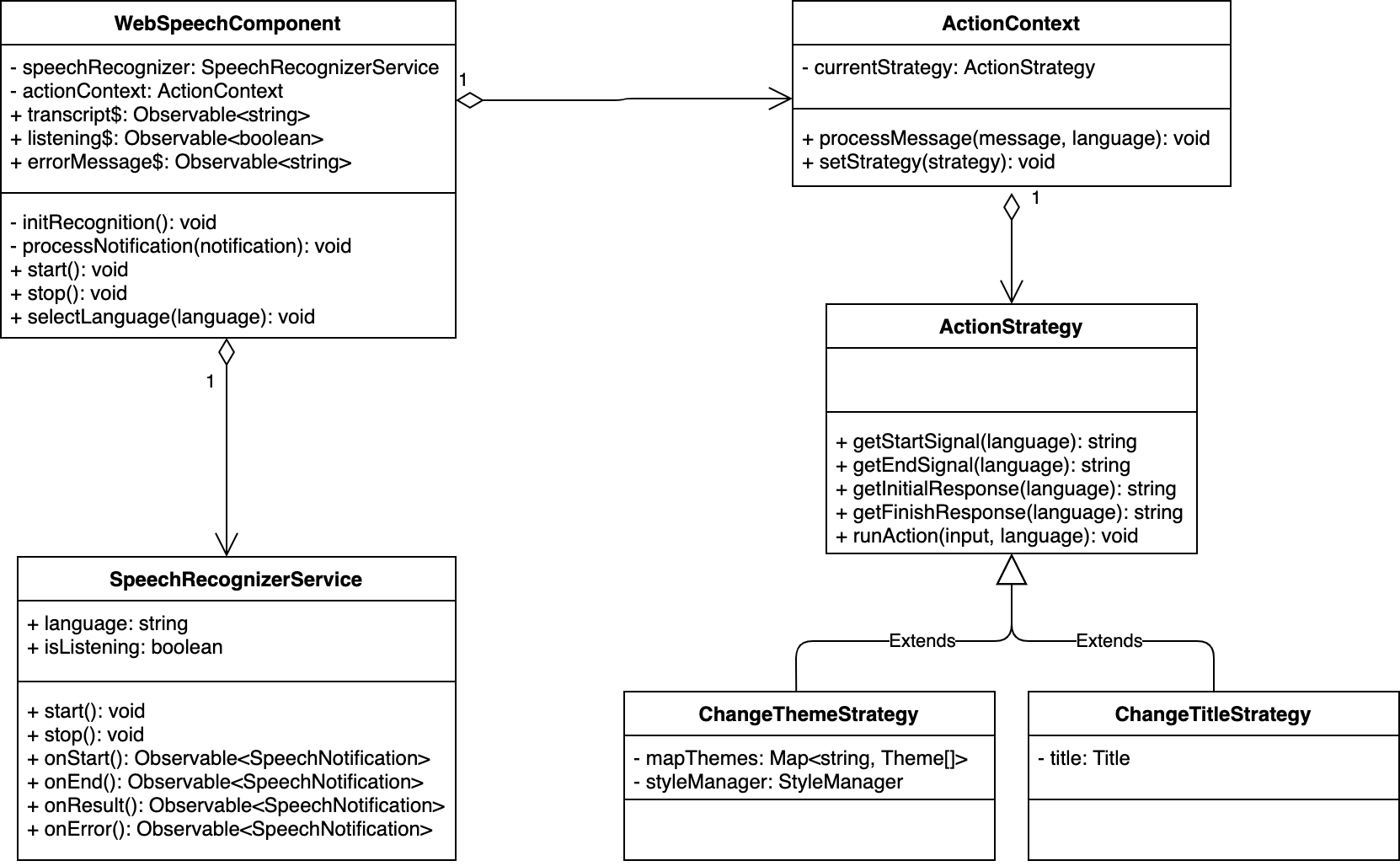
Adding the ActionContext Service and the Strategies
Let’s create the ActionContext, ActionStrategy, ChangeThemeStrategy and ChangeTitleStrategy classes:
ng generate class shared/services/action/action-context
ng generate class shared/services/action/action-strategy
ng generate class shared/services/action/change-theme-strategy
ng generate class shared/services/action/change-title-strategy
// action-context.ts
@Injectable({
providedIn: 'root',
})
export class ActionContext {
private currentStrategy?: ActionStrategy;
constructor(
private changeThemeStrategy: ChangeThemeStrategy,
private changeTitleStrategy: ChangeTitleStrategy,
private titleService: Title,
private speechSynthesizer: SpeechSynthesizerService
) {
this.changeTitleStrategy.titleService = titleService;
}
processMessage(message: string, language: string): void {
const msg = message.toLowerCase();
const hasChangedStrategy = this.hasChangedStrategy(msg, language);
let isFinishSignal = false;
if (!hasChangedStrategy) {
isFinishSignal = this.isFinishSignal(msg, language);
}
if (!hasChangedStrategy && !isFinishSignal) {
this.runAction(message, language);
}
}
runAction(input: string, language: string): void {
if (this.currentStrategy) {
this.currentStrategy.runAction(input, language);
}
}
setStrategy(strategy: ActionStrategy | undefined): void {
this.currentStrategy = strategy;
}
// Private methods omitted. Please refer to the repository to see all the related source code.
// action-strategy.ts
export abstract class ActionStrategy {
protected mapStartSignal: Map<string, string> = new Map<string, string>();
protected mapEndSignal: Map<string, string> = new Map<string, string>();
protected mapInitResponse: Map<string, string> = new Map<string, string>();
protected mapFinishResponse: Map<string, string> = new Map<string, string>();
protected mapActionDone: Map<string, string> = new Map<string, string>();
constructor() {
this.mapFinishResponse.set('en-US', 'Your action has been completed.');
this.mapFinishResponse.set('es-ES', 'La accion ha sido finalizada.');
}
getStartSignal(language: string): string {
return this.mapStartSignal.get(language) || '';
}
getEndSignal(language: string): string {
return this.mapEndSignal.get(language) || '';
}
getInitialResponse(language: string): string {
return this.mapInitResponse.get(language) || '';
}
getFinishResponse(language: string): string {
return this.mapFinishResponse.get(language) || '';
}
abstract runAction(input: string, language: string): void;
}
// change-theme-strategy.ts
@Injectable({
providedIn: 'root',
})
export class ChangeThemeStrategy extends ActionStrategy {
private mapThemes: Map<string, Theme[]> = new Map<string, Theme[]>();
private styleManager: StyleManager = new StyleManager();
constructor(private speechSynthesizer: SpeechSynthesizerService) {
super();
this.mapStartSignal.set('en-US', 'perform change theme');
this.mapStartSignal.set('es-ES', 'iniciar cambio de tema');
this.mapEndSignal.set('en-US', 'finish change theme');
this.mapEndSignal.set('es-ES', 'finalizar cambio de tema');
this.mapInitResponse.set('en-US', 'Please, tell me your theme name.');
this.mapInitResponse.set('es-ES', 'Por favor, mencione el nombre de tema.');
this.mapActionDone.set('en-US', 'Changing Theme of the Application to');
this.mapActionDone.set('es-ES', 'Cambiando el tema de la Aplicación a');
this.mapThemes.set('en-US', [
{
keyword: 'deep purple',
href: 'deeppurple-amber.css',
}
]);
this.mapThemes.set('es-ES', [
{
keyword: 'púrpura',
href: 'deeppurple-amber.css',
}
]);
}
runAction(input: string, language: string): void {
const themes = this.mapThemes.get(language) || [];
const theme = themes.find((th) => {
return input.toLocaleLowerCase() === th.keyword;
});
if (theme) {
this.styleManager.removeStyle('theme');
this.styleManager.setStyle('theme', `assets/theme/${theme.href}`);
this.speechSynthesizer.speak(
`${this.mapActionDone.get(language)}: ${theme.keyword}`,
language
);
}
}
}
// change-title-strategy.ts
@Injectable({
providedIn: 'root',
})
export class ChangeTitleStrategy extends ActionStrategy {
private title?: Title;
constructor(private speechSynthesizer: SpeechSynthesizerService) {
super();
this.mapStartSignal.set('en-US', 'perform change title');
this.mapStartSignal.set('es-ES', 'iniciar cambio de título');
this.mapEndSignal.set('en-US', 'finish change title');
this.mapEndSignal.set('es-ES', 'finalizar cambio de título');
this.mapInitResponse.set('en-US', 'Please, tell me the new title');
this.mapInitResponse.set('es-ES', 'Por favor, mencione el nuevo título');
this.mapActionDone.set('en-US', 'Changing title of the Application to');
this.mapActionDone.set('es-ES', 'Cambiando el título de la Aplicación a');
}
set titleService(title: Title) {
this.title = title;
}
runAction(input: string, language: string): void {
this.title?.setTitle(input);
this.speechSynthesizer.speak(
`${this.mapActionDone.get(language)}: ${input}`,
language
);
}
}
Pay attention to the uses of SpeechSynthesizerService and the places where this service has been called. The moment you use the speak function, the app will use your speakers to answer you.
Source Code and Live Demo
Source Code
Find the complete project in this GitHub repository: https://github.com/luixaviles/web-speech-angular. Do not forget to give it a star ⭐️ or send a Pull Request if you decide to contribute with more features.
Live Demo
Open your Chrome web browser and go to https://luixaviles.com/web-speech-angular/. Review the notes inside the app and test it in English or even Spanish.
Final Words
Even though the demo has been written using Angular and TypeScript, you can apply these concepts and Web APIs with any other JavaScript framework or library.

If you liked this post, be sure to share it with your friends.
You can follow me on Twitter and GitHub to see more about my work.
Thank you for reading!
— Luis Aviles